
")
عیبیابی موثر سرویسهای نرمافزاری

عیبیابی یک مهارت حیاتی برای هر کسی است که برروی سیستمهای محاسباتی توزیعشده کار میکند، اما اغلب به عنوان یک مهارت ذاتی در نظر گرفته میشود که برخی افراد دارند و برخی دیگر ندارند. یکی از دلایل این فرض آن است که برای کسانی که اغلب عیبیابی میکنند، این یک فرآیند ریشهدار است. توضیح نحوه عیبیابی مشکل است، درست مانند توضیح نحوه دوچرخهسواری. با این حال، ما معتقدیم که عیبیابی، هم قابل یادگیری و هم قابل آموزش است.
افراد تازه کار، اغلب هنگام عیبیابی دچار مشکل میشوند زیرا تمرین در حالت ایدهآل به دو عامل بستگی دارد: درک نحوه عیبیابی به طور کلی (یعنی بدون دانش سیستم خاص) و دانش کامل از سیستم. درحالیکه شما میتوانید یک مشکل را فقط با استفاده از فرآیند عمومی و اشتقاق از اصول اولیه بررسی نمایید، ما معمولاً این رویکرد را کم اثرتر از درک نحوه عملکرد چیزها میدانیم. جایگزین کمی برای یادگیری نحوه طراحی و ساخت سیستم وجود دارد.
بیایید به یک مدل کلی از فرآیند عیبیابی نگاه کنیم. خوانندگانی که در عیبیابی مهارت دارند ممکن است با تعاریف و فرآیند ما مخالفت کنند. اگر روش شما برای خودتان موثر است، به شما هشدار داده میشود که متخصص بودن بیش از درک نحوه عملکرد یک سیستم است. تخصص با بررسی اینکه چرا یک سیستم کار نمیکند به دست میآید. راههایی که در آن کارها درست پیش میرود، موارد خاصی از راههایی است که در آن کارها اشتباه میشوند. دلیلی وجود ندارد که به آن پایبند نباشیم.
تئوری
به طور رسمی، میتوانیم فرآیند عیبیابی را بهعنوان کاربرد روش فرضی-قیاسی با توجه به مجموعهای از مشاهدات در مورد یک سیستم و مبنای نظری برای درک رفتار سیستم در نظر بگیریم، ما به طور مکرر دلایل احتمالی شکست را فرض میکنیم و سعی میکنیم آن فرضیهها را آزمایش کنیم.
در یک مدل ایدهآل مانند شکل 1، ما با یک گزارش مشکل شروع میکنیم که به ما میگوید مشکلی در سیستم وجود دارد. سپس میتوانیم به تِلهمتری و گزارشهای سیستم نگاه کنیم تا وضعیت فعلی آن را بفهمیم. این اطلاعات، همراه با دانش ما در مورد نحوه ساخت سیستم، نحوه عملکرد آن و حالتهای خرابی آن، ما را قادر می سازد تا برخی از علل احتمالی را شناسایی نماییم.
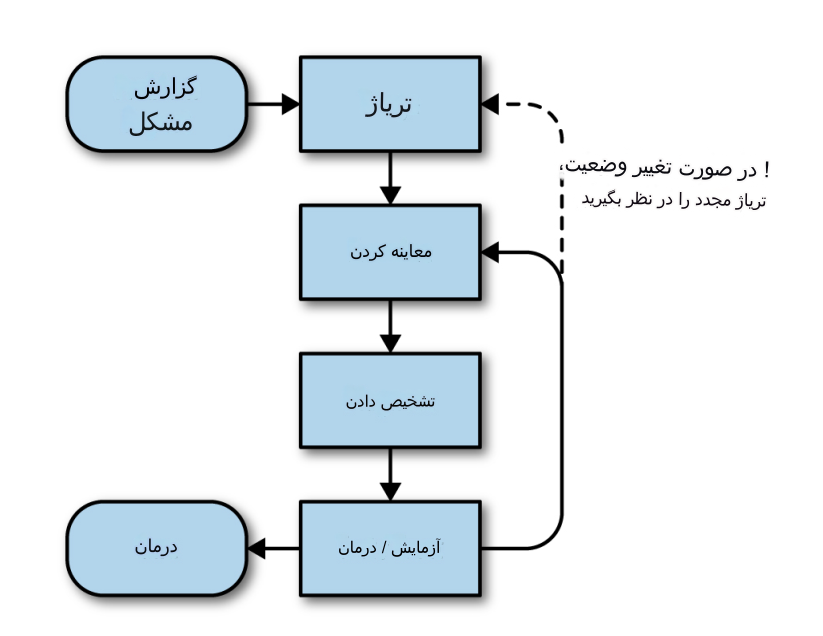
سپس میتوانیم فرضیههای خود را به یکی از دو روش آزمایش کنیم. ما میتوانیم وضعیت مشاهدهشده سیستم را در برابر نظریههای خود با شواهد تأیید کننده یا غیر تایید کننده مقایسه کنیم. یا در برخی موارد، میتوانیم به طور فعال سیستم را «درمان» کنیم - یعنی سیستم را به روشی کنترلشده تغییر دهیم - و نتایج را مشاهده کنیم. این رویکرد دوم، درک ما از وضعیت سیستم و علت(های) احتمالی مشکلات گزارش شده را مجدداً باز میکند. با استفاده از هر یک از این استراتژیها، ما به طور مکرر آزمایش میکنیم تا زمانی که یک علت اصلی شناسایی شود، در این مرحله میتوانیم اقدامات اصلاحی برای جلوگیری از تکرار مشکل را انجام دهیم. البته، رفع علت(های) تقریبی نیازی ندارد همیشه منتظر نوشتن علت اصلی یا پس از مرگ باشد.
دامهای رایج
جلسات عیبیابی ناکارآمد با مشکلاتی در مراحل Triage (تریاژ)، Examine (وارسی) و Diagnose (تشخیص) مواجه میشوند که اغلب به دلیل عدم درک عمیق سیستم است. موارد زیر مشکلات رایجی هستند که باید از آنها اجتناب نمایید:
بررسی علائمی که مرتبط نیستند یا با معنای معیارهای سیستم سازگاری ندارند.
درک نادرست نحوه تغییر سیستم، ورودی های آن، یا محیط آن، به گونهای که به طور ایمن و موثر فرضیهها را آزمایش کند.
ارائه تئوریهای غیرمحتمل در مورد اینکه چه چیزی اشتباه است، با پایبند بودن به دلایل مشکلات گذشته، با این استدلال که از آنجایی که یک بار اتفاق افتاده است، باید دوباره تکرار شود.
جستجوی همبستگیهای جعلی که در واقع تصادفی هستند یا با علل مشترک مرتبط هستند.
رفع مشکلات رایج اول و دوم، موضوع یادگیری سیستم مورد نظر و تجربه کردنِ الگوهای رایج مورد استفاده در سیستمهای توزیع شده است. تله سوم، مجموعهای از اشتباهات منطقی است که میتوان با یادآوری این نکته که همه شکستها به یک اندازه محتمل نیستند، از آن اجتناب کرد.
در نهایت، باید به خاطر داشته باشیم که همبستگی علت نیست: برخی از رویدادهای مرتبط، مثلاً گم شدن بسته (packet) در یک کلاستر و هارد دیسکهای خراب در یک کلاستر، دلایل مشترکی را به اشتراک می گذارند - در این مورد، قطع برق. اگرچه خرابی شبکه به وضوح باعث خرابی هارد دیسک نمیشود. با افزایش اندازه و پیچیدگی سیستمها و نظارت بر معیارهای بیشتر، اجتناب ناپذیر است که رویدادهایی وجود داشته باشند که اتفاقاً به خوبی با رویدادهای دیگر مرتبط باشند.
درک شکست در فرآیند استدلال ما اولین قدم برای اجتناب از آنها و موثرتر شدن در حل مشکلات است. یک رویکرد روشمند برای دانستن آنچه میدانیم، آنچه نمیدانیم، و آنچه باید بدانیم؛ تشخیص اینکه چه چیزی اشتباه رخ داده و چگونه آن را برطرف کنیم را، سادهتر میکند.
در عمل
البته، در عمل، عیبیابی هرگز آنقدر تمیز نیست که مدل ایدهآل ما نشان میدهد که باید باشد. مراحلی وجود دارد که میتواند این فرآیند را، هم برای کسانی که مشکلات سیستمی را تجربه میکنند و هم برای کسانی که به آنها پاسخ میدهند، سازندهتر کند.
گزارش مشکل
هر مشکلی با یک گزارش مشکل شروع میشود، که ممکن است یک هشدار خودکار باشد یا یکی از همکاران شما بگوید: «سیستم کند است». یک گزارش موثر باید رفتار مورد انتظار، رفتار واقعی و در صورت امکان نحوه بازتولید رفتار را به شما بگوید. در حالت ایدهآل، گزارشها باید فرمی ثابت داشته باشند و در یک مکان قابل جستجو، مانند سیستم ردیابی اشکال، ذخیره شوند. در اینجا، تیمهای ما اغلب فرمهای سفارشیشده یا برنامههای وب کوچکی دارند که اطلاعات مربوط به تشخیص سیستمهای خاصی را که پشتیبانی میکنند، درخواست میکنند، که سپس بهطور خودکار یک اشکال را ایجاد و راهاندازی میکنند. این همچنین ممکن است نقطه خوبی برای ارائه ابزارهایی برای گزارشگران مشکل باشد تا بتوانند به تنهایی مشکلات رایج خود را تشخیص داده یا ترمیم کنند.
در شرکت گوگل معمول است که برای هر مشکلی، حتی مواردی که از طریق ایمیل یا پیامرسانی فوری دریافت میشوند، یک باگ باز میکنند. انجام این کار، گزارشی از فعالیتهای تحقیق و اصلاح ایجاد میکند که در آینده میتوان به آنها اشاره کرد. بسیاری از تیمها به چند دلیل از گزارش مستقیم مشکلات به یک فرد منصرف میشوند: این روش یک مرحله اضافی برای رونویسی گزارش به یک اشکال را معرفی میکند، گزارشهایی با کیفیت پایینتر تولید میکند که برای سایر اعضای تیم قابل مشاهده نیست، و تمایل دارد بار حل مشکل را برروی تعداد انگشت شماری از اعضای تیم که گزارشگران اتفاقاً آنها را میشناسند متمرکز کند، به جای فردی که فعلا در حال انجام وظیفه است.
شکسپیر مشکل دارد
شما برای سرویس جستجوی شکسپیر آماده هستید و یک هشدار دریافت میکنید، ShakespeareBlackboxProbe_SearchFailure: مانیتورینگ جعبه سیاه شما در پنج دقیقه گذشته نتوانسته است نتایج جستجو را برای «انواع چیزهای ناشناخته» پیدا کند. سیستم هشدار اشکالی را ثبت کرده است - با پیوندهایی به نتایج اخیر کاوشگر جعبه سیاه و مدخل playbook برای این هشدار آن را به شما اختصاص داده است.
تریاژ (Triage)
هنگامی که یک گزارش مشکل دریافت کردید، گام بعدی این است که مشخص کنید در مورد آن چه کاری باید انجام دهید. مشکلات ممکن است از نظر شدت متفاوت باشند: یک مشکل ممکن است تنها یک کاربر را تحت شرایط بسیار خاص تحت تاثیر قرار دهد (و ممکن است راهحلی داشته باشد)، یا ممکن است منجر به یک قطع کامل جهانی برای یک سرویس شود. پاسخ شما باید برای تأثیر مشکل مناسب باشد: اعلام وضعیت اضطراری «تمام دستها روی عرشه» برای دومی مناسب است، اما انجام این کار برای مورد اول بسیار زیاد است. ارزیابی شدت یک موضوع مستلزم قضاوت مهندسی خوب و اغلب درجه ای از آرامش تحت فشار است.
اولین پاسخ شما در یک قطعی بزرگ ممکن است شروع عیبیابی و تلاش برای یافتن علت اصلی در اسرع وقت باشد. این غریزه را نادیده بگیرید.
درعوض، اقدام شما باید این باشد که سیستم را تا آنجا که میتوانید، تحت هر شرایطی آماده به کار نگه دارید. این ممکن است مستلزم گزینههای اضطراری باشد، مانند هدایت ترافیک از یک خوشه شکسته به سایرین که هنوز کار میکنند، رهاسازی ترافیک به صورت عمده برای جلوگیری از خرابی آبشاری، یا غیرفعال کردن زیرسیستمها برای کاهش بار. توقف خونریزی باید اولویت اول شما باشد. اگر سیستم از بین برود در حالی که شما عامل اصلی هستید، به کاربران خود کمکی نمیکنید. البته، تأکید بر تریاژ سریع، مانع از انجام اقداماتی برای حفظ شواهد مربوط به آنچه اشتباه است، همچون تهیه گزارشها، برای کمک به تجزیه و تحلیل علت ریشهای بعدی نیست.
به خلبانان تازه کار آموزش داده میشود که اولین مسئولیت آنها در مواقع اضطراری، پرواز نگهداشتن هواپیماست. عیبیابی برای رساندن ایمن هواپیما به روی زمین و همه افرادی که در آن هستند، اولویت ثانویه است. این رویکرد برای سیستمهای رایانهای نیز قابل اجرا است: برای مثال، اگر یک باگ، منجر به خرابی دادههای احتمالاً غیرقابل بازیابی شود، مسدود کردن سیستم برای جلوگیری از خرابی بیشتر ممکن است بهتر از ادامه این رفتار باشد.
معاینه کردن (Examine)
ما باید بتوانیم بررسی کنیم که هر جزء در سیستم چه کاری انجام می دهد تا بفهمیم که آیا درست عمل میکند یا خیر.
در حالت ایده آل، یک سیستم مانیتورینگ، معیارهایی را برای سیستم شما ثبت می کند، همانطوریکه در هشدار عملی از دادههای سری زمانی بحث شده است. این معیارها مکان خوبی برای شروع به کشف مشکل هستند. ترسیم سری های زمانی و عملیات روی سری های زمانی می تواند راهی موثر برای درک رفتار قطعات خاصی از یک سیستم و یافتن همبستگی هایی باشد که ممکن است نشان دهد مشکلات از کجا شروع شده اند.
ورود به سیستم یکی دیگر از ابزارهای ارزشمند است. صادر کردن اطلاعات در مورد هر عملیات و وضعیت سیستم این امکان را فراهم میسازد که دقیقاً بفهمیم یک فرآیند در یک نقطه زمانی معین چه کاری انجام می دهد. ممکن است لازم باشد لاگهای سیستم را در یک یا چند فرآیند تجزیه و تحلیل کنید. ردیابی درخواستها در کل پشته با استفاده از ابزارهایی مانند Dapper، راه بسیار قدرتمندی برای درک نحوه عملکرد سیستم توزیعشده فراهم میکند، اگرچه موارد استفاده متفاوت نشاندهنده طراحیهای ردیابی مختلف است.
ثبت وقایع سیستم (Logging)
لاگهای متنی برای اشکالزداییِ واکنشی در زمان واقعی بسیار مفید هستند، در حالی که ذخیره گزارشها در قالب باینری ساختاریافته میتواند ساخت ابزارهایی را برای انجام تجزیه و تحلیل گذشتهنگر با اطلاعات بسیار بیشتر امکانپذیر نماید.
این واقعاً مفید است که چندین سطح مشروح (verbose) در دسترس داشته باشید، همراه با راهی برای افزایش این سطوح در حین پرواز. این قابلیت به شما امکان میدهد بدون نیاز به راهاندازی مجدد فرآیند، یک یا همه عملیات را با جزئیات باورنکردنی بررسی نمایید، در حالیکه همچنان به شما امکان میدهد زمانی که سرویس به طور معمول کار میکند، سطوح مشروح را به حالت قبل برگردانید. بسته به حجم ترافیکی که سرویس شما دریافت میکند، شاید بهتر باشد از نمونهگیری آماری استفاده کنید. برای مثال، ممکن است از هر 1000 عملیات، یکی را نشان دهید.
مرحله بعدی، اضافه کردن یک زبان انتخابی است تا بتوانید بگویید «عملیات منطبق بر X را نشان بده»، برای طیف وسیعی از X—مثلاً RPCها را با اندازه بار زیر 1024 بایت تنظیم کنید یا عملیاتی را که اجرای آنها بیش از 10 میلیثانیه طول کشیده است، یا چه مواردی تابع doSomethingInteresting() را در rpc_handler.py فراخوانی کرده است. حتی ممکن است بخواهید زیرساخت لاگ کردن را طوری طراحی کنید که بتوانید در صورت نیاز، به صورت سریع و انتخابی، آن را فعال کنید.
افشای وضعیت فعلی سومین ترفند در جعبه ابزار ما است. به عنوان مثال، سرورهای Google دارای نقاط پایانی هستند که نمونهای از RPCهایی که اخیراً ارسال یا دریافت شده را نشان میدهند، بنابراین میتوان نحوه ارتباط یک سرور با دیگران را بدون ارجاع به نمودار معماری درک کرد. این نقاط پایانی همچنین هیستوگرامهایی میزان خطا و تأخیر را برای هر نوع RPC نشان میدهند، به طوری که میتوان به سرعت تشخیص داد چه چیزی ناسالم است. برخی از سیستم ها دارای نقاط پایانی هستند که پیکربندی فعلی آنها را نشان می دهد یا اجازه بررسی داده های آنها را می دهد. به عنوان مثال، سرورهای بورگمون گوگل (هشدار عملی از دادههای سری زمانی) میتوانند قوانین نظارتی را که استفاده میکنند نشان دهند و حتی اجازه ردیابی یک محاسبات خاص را به صورت گام به گام میدهند تا معیارهای منبعی که یک مقدار از آن به دست آمده است، مشخص گردد.
اشکال زدایی شکسپیر
با استفاده از پیوند به نتایج مانیتورینگ جعبه سیاه در باگ، متوجه می شوید که کاوشگر (prober)، یک درخواست HTTP GET را به نقطه پایانی /api/search ارسال میکند:
{ ‘search_text’: ‘the forms of things unknown’ }
انتظار میرود پاسخی با کد پاسخ HTTP 200 و بارِ JSON که دقیقاً مطابقت دارد دریافت کند:
[{ "work": "A Midsummer Night's Dream", "act": 5, "scene": 1, "line": 2526, "speaker": "Theseus" }]
سیستم طوری تنظیم شده است که یک بار در دقیقه یک کاوشگر ارسال کند. در طول 10 دقیقه گذشته، تقریباً نیمی از کاوشگرها موفق بوده اند، هرچند بدون الگوی قابل تشخیص. متأسفانه، کاوشگر به شما نشان نمیدهد که در صورت عدم موفقیت، چه چیزی برگردانده شده است. یادداشتی برای رفع آن برای آینده بنویسید.
با استفاده از curl، شما به صورت دستی درخواستهایی را به نقطه پایانی جستجو ارسال میکنید و با کد پاسخ HTTP 502 (Bad Gateway) و بدون بارگیری، پاسخ ناموفق دریافت میکنید. آن دارای یک هدر HTTP به نام X-Request-Trace است که آدرس سرورهای پشتیبان مسئول پاسخگویی به آن درخواست را فهرست میکند. با استفاده از این اطلاعات، اکنون می توانید آن پشتیبان ها را بررسی کنید تا ببینید که آیا آنها به درستی پاسخ میدهند یا خیر.
تشخیص دادن (Diagnose)
درک کامل از طراحی سیستم قطعاً برای ارائه فرضیههای قابل قبول در مورد آنچه اشتباه شده است مفید میباشد، اما برخی از روشهای عمومی نیز وجود دارند که حتی بدون دانش دامنه به شما کمک میکنند.
ساده سازی و کاهش دهید
در حالت ایدهآل، مؤلفهها در یک سیستم دارای رابطهای کاملاً مشخصی هستند و تبدیلهای شناخته شده را از ورودی به خروجی خود انجام میدهند (در مثال ما، با توجه به متن جستجوی ورودی، ممکن است یک مؤلفه، خروجی حاوی تطابقهای احتمالی را برگرداند). سپس می توان به اتصالات بین مؤلفه ها نگاه کرد - یا به طور معادل، به داده های نشان داده شده بین آنها - برای تعیین اینکه آیا یک مؤلفه به درستی کار می کند یا خیر. تزریق دادههای آزمایشی شناختهشده به منظور بررسی اینکه خروجی مورد انتظار است (شکلی از آزمایش جعبه سیاه) در هر مرحله میتواند مؤثر باشد، همانطور که تزریق دادهها برای بررسی علل احتمالی خطاها میتواند مؤثر باشد. داشتن یک کِیس آزمایشی قابل تکرار ثابت، اشکالزدایی را بسیار سریعتر می کند، و ممکن است بتوان از این کِیس در محیط غیرعملیاتی نیز استفاده کرد که در آن تکنیک های تهاجمی یا مخاطره آمیزتری نسبت به محیط عملیات امکان پذیر است. تقسیم و شکست، یک راهحل همهمنظوره خیلی مفید است. در یک سیستم چند لایه که در آن کار در یک پشته از اجزا انجام می شود، اغلب بهتر است که به طور سیستماتیک از یک سر پشته شروع کرده و به سمت دیگر آن کار کنید و هر جزء را به نوبه خود بررسی نمایید. این استراتژی همچنین برای استفاده با خطوط لوله پردازش داده مناسب است. در سیستم های بسیار بزرگ، پیشروی خطی ممکن است بسیار کند باشد. یک راه جایگزین، دو بخشیسازی است، که سیستم را به دو نیم تقسیم میکند و سپس مسیرهای ارتباطی بین اجزای یک طرف و طرف دیگر را بررسی می کند. پس از تعیین اینکه آیا به نظر می رسد یک نیمه به درستی کار می کند یا خیر، این روند را تکرار کنید تا زمانی که احتمالاً فقط یک جزء معیوب باقی بماند.
بپرسید «چی»، «کجا» و «چرا»
یک سیستم معیوب اغلب هنوز در تلاش است کاری را انجام دهد، نه کاری که شما میخواهید انجام دهد. پیدا کردن اینکه چه کاری انجام می دهد، سپس پرسیدن اینکه چرا این کار را انجام می دهد و منابع آن در کجا استفاده می شود یا خروجی آن به کجا می رود، می تواند به شما کمک کند بفهمید که چگونه کارها اشتباه پیش رفته اند.
باز کردن علل یک نشانه
علامت: یک خوشه Spanner تأخیر بالایی دارد و RPCها به سرورهای آن در حال پایان مهلت پاسخگویی هستند (time-out).
چرا؟ وظایف سرور Spanner از تمام زمان CPU خود استفاده میکنند ولی نمی توانند تمام درخواستهایی را که مشتریان ارسال میکنند، پیش ببرند.
در کجای سرور از زمان CPU استفاده میشود؟ پروفایل سرور نشان میدهد که در حال مرتبسازی ورودیهای گزارشهای مربوط به دیسک است.
در کجای کد مرتبسازی گزارش استفاده میشود؟ هنگام ارزیابی یک عبارت منظم (regular expression) در برابر مسیرهای فایل های لاگ.
راه حل: عبارت منظم را بازنویسی کنید تا از بازگشت به عقب جلوگیری نمایید. الگوهای مشابه را در پایگاه کد جستجو کنید. استفاده از RE2 را در نظر بگیرید که به عقب برنمی گردد و رشد خطی زمان اجرا را با اندازه ورودی تضمین می کند.
آخرین تغییر چه بود
سیستمها اینرسی دارند: ما متوجه شدهایم که یک سیستم رایانهای فعال تمایل دارد تازمانیکه یک نیروی خارجی همچون تغییر پیکربندی یا تغییر در نوع بار ارائه شده بر روی آن اثر بگذارد، در حرکت باقی بماند. تغییرات اخیر در یک سیستم میتواند مکانی سازنده برای شروع شناسایی اشتباه باشد.
سیستمهایی که به خوبی طراحی شدهاند باید لاگهای عملیاتی گستردهای برای ردیابی استقرار نسخه جدید و تغییرات پیکربندی در تمام لایههای پشته، از باینریهای سرور که ترافیک کاربر را مدیریت میکنند تا بستههای نصب شده برروی گرههای جداگانه در خوشه، داشته باشند. ارتباط تغییرات در عملکرد و رفتار یک سیستم با سایر رویدادهای سیستم و محیط نیز میتواند در ساخت داشبوردهای نظارت مفید باشد. برای مثال، میتوانید نموداری را که نرخ خطای سیستم را با زمان شروع و پایان استقرار یک نسخه جدید نشان میدهد، همانطوریکه در شکل زیر مشاهده میشود، حاشیهنویسی کنید.
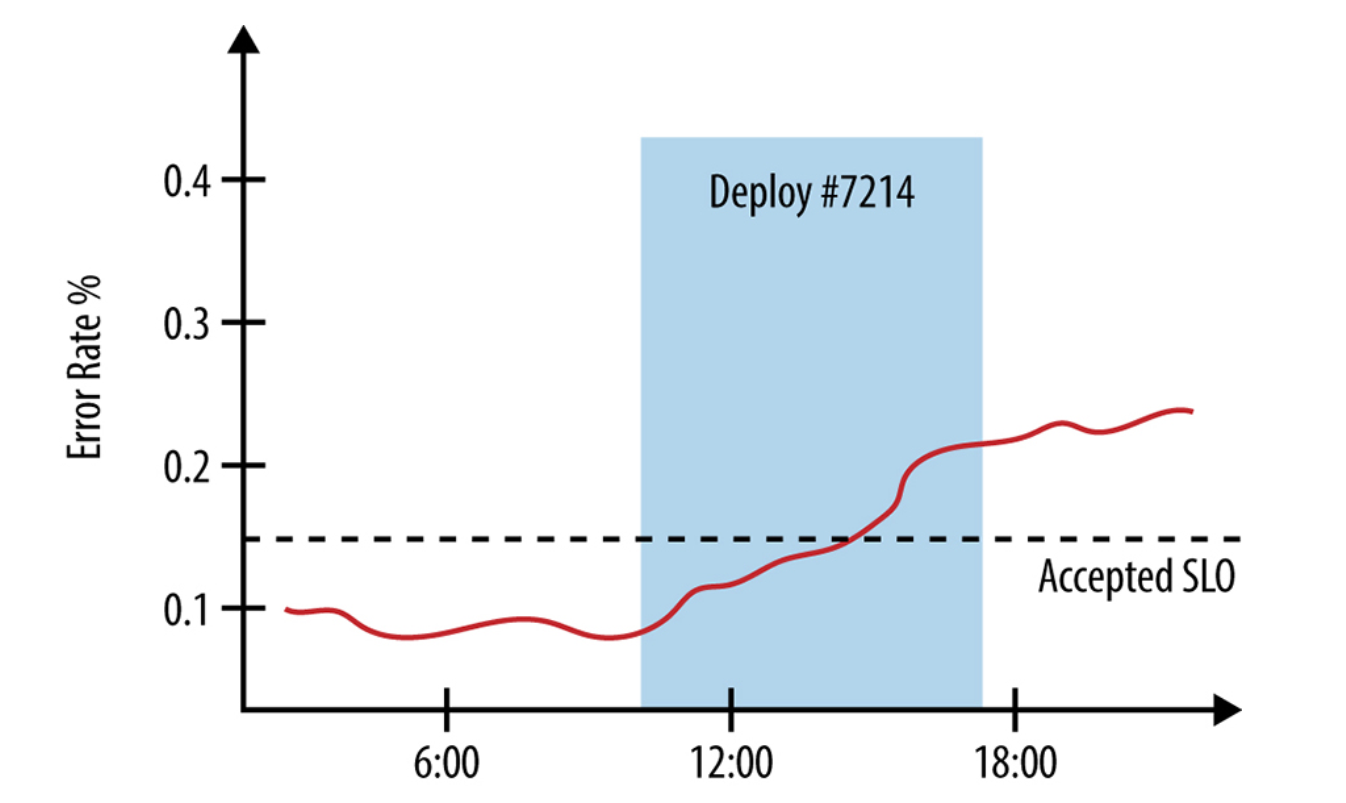
ارسال دستی یک درخواست به نقطه پایانی /api/search (به اشکال زدایی شکسپیر مراجعه کنید) و مشاهده لیست خرابی سرورهای backendای که پاسخ را مدیریت کردهاند، به شما امکان میدهد احتمال اینکه مشکل مربوط به سرور frontend API و توزیع کنندههای بار باشد را کاهش دهید: پاسخ، احتمالاً اگر درخواست مربوطه حداقل به قسمتهای backend جستجو نمیرسید و در آنجا شکست نمیخورد، آن اطلاعات را شامل نمیشد. اکنون میتوانید تلاشهای خود را بر روی backendها متمرکز کنید - گزارشهای آنها را تجزیه و تحلیل کنید، درخواستهای آزمایشی را ارسال نمایید تا ببینید چه پاسخهایی را برمیگردانند، و سپس معیارهای صادر شدهشان را بررسی کنید.
تشخیصهای خاص
درحالیکه ابزارهای عمومی که قبلاً توضیح داده شد، در طیف گسترده ای از حوزه های مشکل مفید هستند، احتمالاً ساختن ابزارها و سیستمهایی برای کمک به تشخیص خدمات خاص شما نیز، مفید خواهد بود. Google SRE بیشتر وقت خود را صرف ساخت چنین ابزارهایی میکند. درحالیکه بسیاری از این ابزارها لزوماً مختص یک سیستم خاص هستند، حتماً به دنبال نقاط مشترک بین سرویسها و تیمها باشید تا از تلاشهای تکراری جلوگیری نمایید.
تست و درمان کنید
هنگامیکه فهرست کوتاهی از علل احتمالی را تهیه کردید، زمان آن فرا رسیده است که سعی کنید علت اصلی مشکل واقعی را پیدا کنید. با استفاده از روش تجربی، میتوانیم سعی کنیم فرضیه های خود را رد یا بپذیریم. به عنوان مثال، فرض کنید ما فکر میکنیم مشکل ناشی از خرابی شبکه بین یک سرور برنامه و یک سرور پایگاه داده است، یا به دلیل امتناع پایگاه داده از پذیرش اتصالات. تلاش برای اتصال به پایگاه داده با همان اعتباری که منطق سرور برنامه استفاده میکند، میتواند فرضیه دوم را رد کند، در حالیکه پینگ کردن سرور پایگاه داده ممکن است بسته به توپولوژی شبکه، قوانین فایروال و سایر عوامل، بتواند فرضیه اول را رد کند. دنبال کردن کد و تلاش برای تقلید از نمایش کد، به صورت گام به گام، ممکن است دقیقاً به آنچه اشتباه است، اشاره نماید.
چندین ملاحظه وجود دارد که باید هنگام طراحی تستها در نظر داشت (که ممکن است به سادگی ارسال پینگ یا به پیچیدگی حذف ترافیک از یک کلاستر و تزریق درخواستهای خاص برای یافتن شرایط رقابتی باشد):
یک آزمون ایدهآل باید جایگزینهای متقابل انحصاری داشته باشد، به طوری که بتواند گروهی از فرضیهها را در مجموعهای از فرضیهها قبول کرده و گروهی دیگر را رد کند. در عمل، دستیابی به این امر ممکن است دشوار باشد.
ابتدا موارد بدیهی را در نظر بگیرید: با در نظر گرفتن خطرات احتمالی برای سیستم از طریق آزمون، آزمون ها را به ترتیب احتمال کاهشی انجام دهید. احتمالاً قبل از بررسی اینکه آیا تغییر پیکربندی اخیر، دسترسی کاربر به دستگاه دوم را قطع کرده است، آزمون مشکلات اتصال به شبکه بین دو ماشین منطقیتر باشد.
یک آزمون ممکن است به دلیل عوامل مخدوش کننده نتایج گمراه کننده ارائه دهد. به عنوان مثال، یک قانون فایروال ممکن است فقط از یک آدرس IP خاص اجازه دسترسی را بدهد، که ممکن است باعث شود پینگ پایگاه داده از ایستگاه کاری شما با شکست مواجه شود، حتی اگر پینگ از دستگاه سرور برنامه با موفقیت انجام شود.
آزمونهای فعال ممکن است عوارض جانبی داشته باشند که نتایج آزمونهای آینده را تغییر دهد. به عنوان مثال، اجازه دادن به یک فرآیند برای استفاده از CPUهای بیشتر ممکن است عملیات را سریعتر کند، اما ممکن است احتمال مواجهه با رقابت داده را افزایش دهد. به طور مشابه، فعال کردن گزارشگیری پرمخاطب ممکن است مشکل تأخیر را حتی بدتر کند و تحلیل شما را مبهم سازد: آیا مشکل به خودی خود بدتر میشود یا به دلیل ورود به سیستم؟
برخی از تستها ممکن است قطعی نباشند، بلکه فقط پیشنهاد ارائه دهند. ایجاد شرایط رقابت یا بنبست بهموقع و قابل تکرار میتواند بسیار دشوار باشد، بنابراین ممکن است به شواهد کمتر مطمئنی مبنی بر اینکه آیا اینها دلایل مربوطه هستند، روی آورید.
از ایدههایی که داشتید، آزمونهایی که انجام دادید و نتایجی که مشاهده نمودید، یادداشتهای واضحی بردارید. به خصوص وقتی با موارد پیچیدهتر و طولانیتر سروکار دارید، این مستندات ممکن است برای کمک به یادآوری دقیق اتفاقات و جلوگیری از تکرار این مراحل بسیار مهم باشد. اگر تست فعال را با تغییر یک سیستم انجام دادید - به عنوان مثال با دادن منابع بیشتر به یک فرآیند که تغییرات را به شیوهای سیستماتیک و مستند انجام میدهد، به شما کمک میکند تا سیستم را به تنظیمات اولیه خود بازگردانید، نه اینکه در یک پیکربندی ناشناخته درهم برهم اجرا شود.
نتایج منفی جادو می کنند
یک نتیجه "منفی" یک نتیجه آزمایشی است که در آن اثر مورد انتظار وجود ندارد - یعنی هر آزمایشی که طبق برنامهریزی انجام نمی شود. این شامل طرحهای جدید، اکتشافی یا فرآیندهای انسانی است که در سیستمهایی که جایگزین میشوند، بهبود نمییابند.
نتایج منفی را نباید نادیده گرفت یا تخفیف داد.درک اشتباه شما ارزش زیادی دارد: یک نتیجه منفی واضح میتواند برخی از سختترین سوالات طراحی را حل کند. غالباً یک تیم، دو طرح به ظاهر معقول دارد، اما پیشرفت در یک جهت باید به سؤالات مبهم و گمانهزنی در مورد اینکه آیا جهت دیگر ممکن است بهتر باشد، پاسخ دهد.
آزمون¬ها با نتایج منفی قطعی هستند.آنها در مورد محیط عملیات، فضای طراحی، یا محدودیتهای کارایی یک سیستم موجود، چیز خاصی به ما میگویند. آنها میتوانند به دیگران کمک کنند تا تعیین نمایند که آیا آزمایشها یا طرحهای خودشان ارزشمند هستند یا خیر. به عنوان مثال، یک تیم توسعه دهنده ممکن است تصمیم به استفاده از یک وبسرور خاص بگیرد، زیرا میتواند تنها 800 اتصال از 8000 اتصال مورد نیاز را قبل از شکست به دلیل «رقابت بر سر قفل» انجام دهد. هنگامی که تیم توسعه بعدی تصمیم به ارزیابی وب سرورها می گیرد، به جای شروع از ابتدا، می توانند از این نتیجه منفی که قبلاً به خوبی مستند شده است به عنوان نقطه شروع برای تصمیم گیری سریع استفاده کنند که آیا (الف) به کمتر از 800 اتصال نیاز دارند یا(ب) مشکلات قفل حل شده است.
حتی زمانی که نتایج منفی مستقیماً به آزمایش شخص دیگری اعمال نمیشود، دادههای تکمیلی جمعآوریشده میتواند به دیگران کمک کند آزمایشهای جدید را انتخاب کنند یا از دامهایی در طرحهای قبلی جلوگیری کنند. محکهای ریز، ضدالگوهای مستند شده، و کالبدشکافی پروژه همه از این دسته هستند. هنگام طراحی آزمون باید دامنه نتیجه منفی را در نظر بگیرید، زیرا یک نتیجه منفی گسترده یا قوی به همتایان شما کمک بیشتری میکند.
ابزارها و روشها میتوانند بیشتر از این آزمون دوام بیاورند و به کار آینده اطلاع دهند.به عنوان مثال، ابزارهای محک زدن و مولدهای بار می توانند به آسانی از یک آزمایش تایید نشده به عنوان یک آزمایش پشتیبان نتیجه بگیرند. بسیاری از وب مسترها از کار دشوار و جزئیات محوری که Apache Bench، یک تست بارگذاری سرور وب تولید کرده است، سود بردهاند، حتی اگر اولین نتایج آن احتمالاً ناامید کننده بود.
ساخت ابزار برای آزمایشهای تکرارشونده نیز میتواند مزایای غیرمستقیم داشته باشد: اگرچه برنامهای که میسازید ممکن است از داشتن پایگاه داده خود بر روی SSD یا ایجاد شاخصهایی برای کلیدهای متراکم سودی نبرد، در هر صورت در برنامه بعدی ممکن است اینکار انجام شود. نوشتن یک اسکریپت که به شما امکان میکند به راحتی این تغییرات پیکربندی را امتحان کنید، تضمین میکند بهینهسازی ها را در پروژه بعدی خود فراموش نکرده و از دست ندهید.
انتشار نتایج منفی، فرهنگ دادهمحور صنعت ما را بهبود میبخشد.حسابداری برای نتایج منفی و بیاهمیت آماری، جهتگیری در معیارهای ما را کاهش میدهد و مثالی برای دیگران از نحوه پذیرش کامل عدم قطعیت ارائه میکند. با انتشار همه چیز، دیگران را تشویق میکنید که همین کار را انجام دهند و همه افراد در صنعت به طور جمعی خیلی سریعتر یاد میگیرند.
>نتایج کار خود را منتشر کنید.اگر به نتایج یک آزمایش علاقهمند هستید، احتمال زیادی وجود دارد که افراد دیگر نیز علاقهمند باشند. وقتی نتایج را منتشر میکنید، آن افراد مجبور نیستند خودشان آزمایش مشابهی را طراحی و اجرا کنند. اجتناب از گزارش نتایج منفی وسوسه انگیز و رایج است زیرا به راحتی می توان دریافت که آزمایش «شکست خورده است». برخی از آزمایشها محکوم به فنا هستند، و معمولاً با بررسی بیشتر مورد توجه قرار میگیرند. بسیاری از آزمایشهای دیگر به سادگی گزارش نمیشوند، زیرا افراد به اشتباه معتقدند نتایج منفی پیشرفت نیست.
نقش خود را با گفتن طرحها، الگوریتمها و کارهای تیمی که رد کردهاید، برای همه نشان دهید. با درک این نکته که نتایج منفی بخشی از ریسکپذیری متفکرانه است و با هر آزمایشی که به خوبی طراحی شده باشد، همتایان خود را تشویق کنید. نسبت به هر سند طراحی، بررسی عملکرد یا مقالهای که به شکست اشارهای نمیکند، شک داشته باشید. چنین سندی به طور بالقوه یا به شدت فیلتر شده است، یا نویسنده در روشهای خود دقیق نبوده است.
مهمتر از همه، نتایجی را که شگفتانگیز میدانید منتشر کنید تا دیگران از جمله خود شما در آینده متعجب نشوند.
درمان
در حالت ایده آل، اکنون مجموعهای از علل احتمالی را به یک علت محدود کرده اید. بعد، ما می خواهیم ثابت کنیم که علت واقعی آن است. اثبات قطعی اینکه یک عامل معین باعث ایجاد مشکل شده است - با بازتولید آن به دلخواه خود - میتواند در سیستمهای عملیاتی دشوار باشد. اغلب، ما فقط میتوانیم عوامل علّی احتمالی را به دلایل زیر پیدا کنیم:
سیستمها پیچیده هستند.کاملاً محتمل است که عوامل متعددی وجود داشته باشد که هر کدام به تنهایی علت نیستند، اما به طور مشترک علت هستند. سیستم های واقعی نیز اغلب وابسته به مسیر هستند، به طوری که قبل از وقوع یک شکست باید در یک وضعیت خاص باشند.
بازتولید مشکل در یک سیستم عملیاتی ممکن است یک گزینه نباشد،یا به دلیل پیچیدگی وارد کردن سیستم به حالتی که می تواند باعث خرابی شود، یا به این دلیل که ممکن است خرابی بیشتر غیرقابل قبول باشد. داشتن یک محیط غیرعملیاتی می تواند این چالش ها را کاهش دهد، هرچند به قیمت اجرای یک نسخه دیگر از سیستم باشد.
هنگامیکه عوامل ایجاد مشکل را پیدا کردید، زمان آن است که در مورد مشکل سیستم، نحوه ردیابی مشکل، نحوه رفع مشکل و نحوه جلوگیری از تکرار آن یادداشت برداری کنید.
آسانسازی عیبیابی
راههای زیادی برای سادهسازی و تسریع عیبیابی وجود دارد. احتمالا اساسیترین آنها عبارتند از:
ایجاد قابلیت مشاهده با معیارهای جعبه سفید و لاگهای ساختاریافته در هر جزء از ابتدا
طراحی سیستمهایی با رابطهای قابل درک و قابل مشاهده بین اجزا
اطمینان از اینکه اطلاعات به روشی ثابت در سراسر یک سیستم در دسترس است - به عنوان مثال، استفاده از یک شناسه درخواست منحصر به فرد در طول RPCهای تولید شده توسط اجزای مختلف - نیاز به کشف اینکه کدام ورودی لاگ در یک جزء بالادستی با یک ورودی لاگ در یک گزارش مطابقت دارد را کاهش میدهد و همینطور کشف جزء پایین دست و سرعت بخشیدن به زمان تشخیص و بهبودی مورد نیاز است.
وجود مشکلات در نمایش صحیح وضعیت واقعیت در یک تغییر کد یا در یک تغییر محیط، اغلب منجر به نیاز به عیبیابی میشود. سادهسازی، کنترل و ثبت چنین تغییراتی میتواند نیاز به عیبیابی را کاهش دهد و در صورت وقوع آن را آسانتر نماید.
شرکت مهندس پیشگان آزمون افزار یاس، خدمات زیر را در حوزهارزیابی و پایش کارایی نرم افزارارائه می دهد:
آموزش روشهای ارزیابی کارایی سامانه های نرم افزاری از طریق آزمونهای بار و فشار
اجرای آزمونهای بار و فشار برروی سامانه های نرم افزاری
تهیه و آموزش ابزارهایتست پرفورمنس(تست بار و فشار) همچونWPLTو LoadTest
پایش و مانیتورینگ شاخص های کارایی سامانه های نرم افزاری از طریق ابزارهای مدیریت کارایی همچونAppDynamicsو DynaTrace
نویسنده:شرکت مهندس پیشگان آزمون افزار یاس
![]() مراجع
مراجع