
")
کارایی و مقیاس بندی JDBC و پایگاه داده

یک برنامه سازمانی باید داده ها را در سریع ترین زمان ممکن ذخیره و بازیابی کند. در مدیریت کارایی برنامه، دو معیار مهم، زمان پاسخ و توان عملیاتی است.
هرچه زمان پاسخ کمتر باشد، یک برنامه پاسخگو تر میشود. بنابراین، زمان پاسخ، معیار عملکرد است. مقیاس بندی در مورد حفظ زمان پاسخ پایین و در عین حال افزایش بار سیستم است، بنابراین توان عملیاتی معیار مقیاس پذیری است.
زمان پاسخ و توان عملیاتی
از آنجاییکه این مقاله بر روی دسترسی به داده های با کارایی بالا متمرکز شده است، مرزهای سیستم مورد آزمایش در سطح مدیر تراکنش قرار دارند. زمان پاسخ تراکنش به عنوان زمانی که برای تکمیل یک تراکنش طول می کشد اندازه گیری می شود و بنابراین بخش های زمانی زیر را در بر میگیرد:
زمان دستیابی به اتصال پایگاه داده
زمان لازم برای ارسال تمام عبارات پایگاه داده از طریق سیم
زمان اجرا برای همه عبارات دریافتی
مقدار زمان ارسال نتیجه به سرویس گیرنده پایگاه داده
مقدار زمان بیکاری تراکنش به دلیل محاسبات سطح برنامه قبل از انتشار
زمانی که تراکنش به دلیل محاسبات در سطح برنامه قبل از آزاد کردن اتصال پایگاه داده بیکار است.
T=tacq + treq + texec + tres + tidle
توان عملیاتی به عنوان نرخ تکمیل بار ورودی تعریف می شود. در زمینه پایگاه داده، توان عملیاتی را می توان به عنوان تعداد تراکنش های انجام شده در یک بازه زمانی معین محاسبه کرد.
از این تعریف می توان نتیجه گرفت که با کاهش زمان لازم برای اجرای یک تراکنش، سیستم می تواند درخواست های بیشتری را پاسخ دهد.
با آزمایش در برابر یک اتصال پایگاه داده واحد، توان عملیاتی اندازهگیری شده، مبنایی برای بهبودهای بیشتر مبتنی بر همزمانی میشود.
X(N)=X(1)*C(N)
در حالت ایدهآل، اگر سیستم به صورت خطی مقیاسبندی میشد، افزودن اتصالات پایگاهداده بیشتر باعث افزایش توان عملیاتی متناسب میشد. با توجه به مشاجره بر سر منابع پایگاه داده و هزینه حفظ انسجام در چندین جلسه پایگاه داده همزمان، افزایش توان عملیاتی نسبی به جای خط مستقیم از یک منحنی پیروی می کند.
USL (قانون مقیاس پذیری جهانی) می تواند حداکثر توان عملیاتی نسبی (ظرفیت سیستم) را در رابطه با تعداد مولدهای بار (اتصالات پایگاه داده) بصورت تقریبی بیان کند.
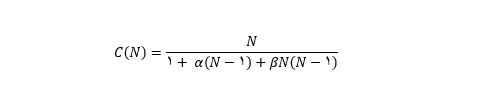
C - افزایش توان نسبی برای سطح همزمانی داده شده
α - ضریب اختلاف (بخش قابل سریال سازی روال پردازش داده ها)
β - ضریب همسویی (هزینه حفظ ثبات در تمام جلسات پایگاه داده همزمان)
وقتی ضریب همسویی صفر باشد، USL با قانون Amdahl همپوشانی دارد. این مشاجره تأثیری بر افزایش مقیاس پذیری دارد. از سوی دیگر، انسجام مسئول نقطه عطف در منحنی مقیاس پذیری است و با افزایش تعداد جلسات همزمان، تأثیر آن بیشتر می شود.
نمودار زیر افزایش توان نسبی را هنگامی که ضرایب USL (β,α) ، روی مقادیر زیر (0.1، 0.0001) تنظیم میشوند، نشان میدهد. محور x تعداد جلسات همزمان (N) و محور y افزایش ظرفیت نسبی (C) را نشان می دهد.
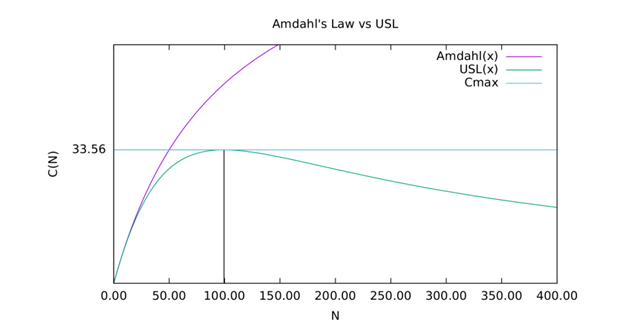
تعداد مولدهای بار (اتصالات پایگاه داده)، که سیستم برای آنها حداکثر ظرفیت خود را دارد، صرفاً به ضرایب USL بستگی دارد.
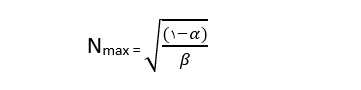
افزایش ظرفیت حاصل نسبت به حداقل توان عملیاتی است، بنابراین ظرفیت مطلق سیستم به صورت زیر به دست می آید:
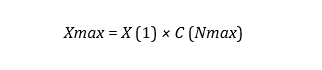
مرزهای ارتباطات پایگاه داده
هر اتصال به یک سوکت TCP از مشتری (برنامه) به سرور (پایگاه داده) نیاز دارد. تعداد کل اتصالات ارائه شده توسط یک سرور پایگاه داده به منابع سخت افزاری اساسی بستگی دارد و یافتن تعداد اتصالات یک سرور می تواند از طریق اندازه گیری ها و مدل های مقیاس پذیری اثبات شده امکان پذیر باشد.
SQL Server 2016 و MySQL 5.7 از مدیریت اتصال مبتنی بر رشته استفاده می کنند. PostgreSQL 9.5 از یک فرآیند سیستم عامل برای هر اتصال جداگانه استفاده می کند. در سیستم های ویندوز، اوراکل از رشته ها استفاده می کند، در حالی که در لینوکس از اتصالات مبتنی بر فرآیند استفاده می کند
نگاهی به داخل سیستم پایگاه داده، وابستگی شدید به منابع CPU، حافظه و دیسک را نشان می دهد. از آنجاییکه عملیات ورودی/خروجی پرهزینه است، پایگاه داده از یک مخزن بافر برای نگاشت داده های زیرین و صفحات فهرست به حافظه استفاده می کند. تغییرات ابتدا در حافظه اعمال میشوند و به صورت دستهای روی دیسک فلاش میشوند تا عملکرد نوشتن بهتری داشته باشند.
حتی اگر تمام ایندکس ها به طور کامل در حافظه پنهان باشند، اگر بلوک های داده درخواستی در مخزن بافر حافظه ذخیره نشده باشند، ممکن است دسترسی به دیسک همچنان رخ دهد. نه تنها پرس و جوها ممکن است ترافیک ورودی/خروجی ایجاد کنند، بلکه تراکنش و گزارشهای انجام مجدد نیاز به فلاش شدن دورهای ساختارهای داده درون حافظه دارند تا دوام به خطر نیفتد.
برای ارائه یکپارچگی داده ها، هر سیستم پایگاه داده رابطه ای باید از قفل های انحصاری برای محافظت از بلوک های داده (ردیف ها و شاخص ها) از به روز رسانی همزمان استفاده کند. این درست است حتی اگر سیستم پایگاه داده از MVCC (کنترل همزمانی چند نسخه) استفاده کند زیرا در غیر این صورت اتمی بودن به خطر می افتد.
این به این معنی است که برنامه های پایگاه داده با توان عملیاتی بالا در CPU، حافظه، دیسک و قفل ها اختلاف نظر دارند. هنگامی که تمام منابع سرور پایگاه داده در حال استفاده هستند، اضافه کردن حجم کاری بیشتر تنها باعث افزایش اختلاف و در نتیجه کاهش توان عملیاتی می شود.
منابع ممکن است به دلیل پیکربندی نامناسب سیستم اشباع شوند، بنابراین اولین گام برای بهبود توان عملیاتی سیستم، تنظیم آن بر اساس الگوهای دسترسی به داده های فعلی است.
کاهش زمان پاسخ نه تنها باعث پاسخگویی بیشتر برنامه می شود، بلکه می تواند توان عملیاتی را نیز افزایش دهد. با این حال، زمان پاسخ به تنهایی در یک محیط بسیار همزمان کافی نیست. برای حفظ زمان پاسخ کران بالایی ثابت، ظرفیت سیستم باید نسبت به توان عملیاتی درخواست ورودی افزایش یابد. افزودن منابع بیشتر میتواند مقیاسپذیری را تا یک نقطه خاص بهبود بخشد، که فراتر از آن افزایش ظرفیت شروع به کاهش میکند.
Scaling up and Scaling out
مقیاس بندی اثر افزایش ظرفیت با افزودن منابع بیشتر است. مقیاس عمودی (scaling up) به معنای افزودن منابع به یک ماشین واحد است. افزایش تعداد ماشین های موجود را مقیاس بندی افقی (scaling out) می گویند. به طور سنتی، افزودن منابع سخت افزاری بیشتر به سرور پایگاه داده، روش ارجح برای افزایش ظرفیت پایگاه داده بوده است. پایگاه های داده رابطه ای در اواخر دهه هفتاد پدیدار شدند و برای دو دهه و نیم، فروشندگان پایگاه داده از پیشرفت های سخت افزاری به دنبال روندهای قانون مور استفاده کردند.
مدیریت سیستم های توزیع شده بسیار پیچیده تر از سیستم های متمرکز است و به همین دلیل است که مقیاس افقی چالش برانگیزتر از مقیاس بندی عمودی است. از سوی دیگر، با همان قیمت یک سرور اختصاصی با کارایی بالا، می توان چندین ماشین را خریداری کرد که مجموع منابع موجود (CPU، حافظه، حافظه دیسک) بیشتر از یک سرور اختصاصی واحد است. هنگام تصمیم گیری اینکه کدام روش مقیاس بندی برای یک سیستم سازمانی مناسب تر است، باید هم قیمت (سخت افزار و مجوزها) و هم هزینه های توسعه و عملیات ذاتی را در نظر گرفت.
فیس بوک که بر روی بسیاری از پروژه های منبع باز (مانند PHP، MySQL) ساخته شده است، از معماری مقیاس افقی برای تطبیق حجم عظیم ترافیک خود استفاده می کند.
StackOverflow بهترین نمونه از معماری مقیاس بندی عمودی است. جف اتوود در یکی از پست های وبلاگ خود توضیح داد که قیمت مجوزهای ویندوز و SQL Server یکی از دلایل عدم انتخاب رویکرد مقیاس افقی است. مهم نیست که چقدر قدرتمند باشد، یک سرور اختصاصی همچنان یک نقطه خرابی(SPOF) است و اگر سیستم دیگر در دسترس نباشد، توان عملیاتی به صفر می رسد. به همین دلیل، تکرار پایگاه داده در بسیاری از سیستم های سازمانی اختیاری نیست.
تکثیر Master-Slave
برای سیستمهای سازمانی که نسبت خواندن/نوشتن بالاست، یک طرح تکرار Master-Slave برای افزایش دسترسی مناسب است.
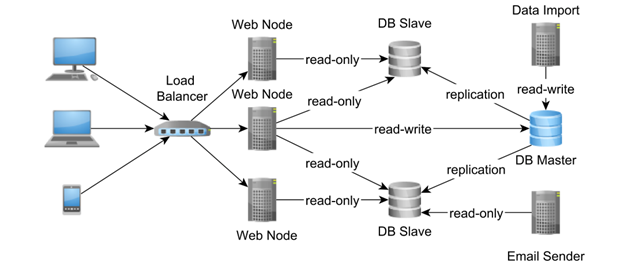
Master سیستم ثبت است و تنها گره ای که می نویسد. تمام تغییرات ثبت شده توسط گره Master بر روی Slaves نیز پخش می شود. یک تکرار دودویی از گره اصلی WAL (Write Ahead Log) استفاده می کند در حالی که یک تکرار مبتنی بر دستور، عبارات دقیق اجرا شده در Master را در ماشین های Slave تکرار می کند.
همانندسازی ناهمزمان بسیار رایج است، به خصوص زمانی که گره های Slave بیشتری برای به روز رسانی وجود دارد. گره های Slave در نهایت سازگار هستند زیرا ممکن است از Master عقب بمانند. در صورت خرابی گره Master، یک فرآیند رای گیری در کل خوشه باید Master جدید (معمولاً گرهی با آخرین رکورد به روز رسانی) از لیست همه Slave های موجود انتخاب شود.
توپولوژی تکرار ناهمزمان نیز به عنوان آماده به کار گرم نامیده می شود زیرا فرآیند انتخابات به صورت آنی اتفاق نمی افتد.
اکثر سیستم های پایگاه داده به قیمت افزایش زمان پاسخ تراکنش، یک گره Slave سنکرون را امکان پذیر می کنند (Master باید انتظار برای تایید نود Slave همزمان را مسدود کند). در صورت خرابی گره اصلی، مکانیسم شکست خودکار می تواند گره Slave سنکرون را برای تبدیل شدن به Master جدید ارتقا دهد.
داشتن یک Slave سنکرون به سیستم اجازه می دهد تا از سازگاری داده ها در صورت خرابی گره اصلی اطمینان حاصل کند زیرا Slave سنکرون یک کپی دقیق از Master است. تکثیر همزمان Master-Slave همچنین توپولوژی آماده به کار داغ نامیده می شود زیرا Slave سنکرون به راحتی برای جایگزینی گره Master در دسترس است.
هنگامی که فقط گره های Slave ناهمزمان در دسترس هستند، گره Slave جدید انتخاب شده ممکن است از Master شکست خورده عقب بماند، در این صورت ثبات و دوام با تاخیر کمتر و توان عملیاتی بالاتر معامله می شود.
جدای از حذف یک نقطه شکست، تکثیر پایگاه داده همچنین می تواند بدون تأثیر بر زمان پاسخ، توان عملیاتی تراکنش را افزایش دهد. در توپولوژی Master-Slave، گرههای Slave میتوانند تراکنشهای فقط خواندنی را بپذیرند، بنابراین ترافیک خوانده شده را از گره Master دور میکنند.
گرههای Slave اتصالات فقط خواندنی موجود را افزایش میدهند و اختلاف منابع گره اصلی را کاهش میدهند، که به نوبه خود میتواند زمان پاسخ خواندن و نوشتن تراکنش را نیز کاهش دهد. اگر گره Master دیگر نتواند با ترافیک فزاینده خواندن و نوشتن همراهی کند، تکرار MultiMaster ممکن است جایگزین بهتری باشد.
تکثیر Master-Master
در یک طرح تکرار Multi-Master، همه گره ها برابر هستند و می توانند هر دو تراکنش فقط خواندنی و خواندنی را بپذیرند. تقسیم بار بین گره های متعدد تنها می تواند توان عملیاتی تراکنش را افزایش دهد و زمان پاسخ را نیز کاهش دهد.
با این حال، از آنجایی که سیستم های توزیع شده همه چیز در مورد مبادله هستند، اطمینان از سازگاری داده ها در طرح تکرار Multi-Master چالش برانگیز است زیرا دیگر یک منبع واحد از حقیقت وجود ندارد. همان داده ها را می توان همزمان در گره های جداگانه تغییر داد، بنابراین احتمال بروز رسانی متناقض وجود دارد. طرح تکرار می تواند از تضادها جلوگیری کند یا می تواند آنها را شناسایی کرده و الگوریتم حل تعارض خودکار را اعمال کند.
برای جلوگیری از تداخل، می توان از پروتکل commit دو فازی استفاده کرد تا تمام گره های شرکت کننده را در یک تراکنش توزیع شده ثبت کند. این طراحی به تمام گرهها اجازه میدهد تا به قیمت افزایش زمان پاسخ تراکنش (با کاهش سرعت عملیات نوشتن) همگام باشند.
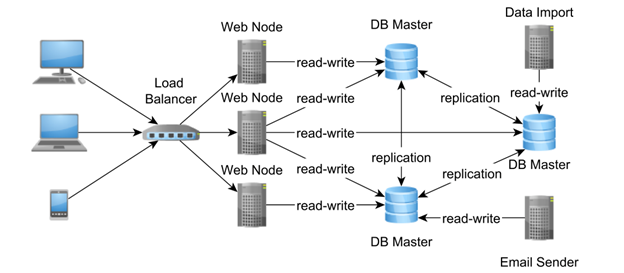
اگر گره ها توسط یک WAN (شبکه گسترده) از هم جدا شوند، تاخیرهای همگام سازی ممکن است به طور چشمگیری افزایش یابد. اگر یک گره دیگر قابل دسترسی نباشد، همگامسازی با شکست مواجه میشود و تراکنش در همه Masterها برمیگردد.
اگرچه اجتناب از تضاد از منظر سازگاری داده ها بهتر است، تکرار همزمان ممکن است زمان پاسخ تراکنش بالایی داشته باشد. از سوی دیگر، به قیمت حل تعارضات به روز رسانی، تکرار ناهمزمان می تواند توان عملیاتی بهتری را ارائه دهد، تکرار ناهمزمان Multi-Master به تشخیص تضاد و یک الگوریتم حل تعارض خودکار نیاز دارد. هنگامی که یک تضاد شناسایی می شود، حل خودکار سعی می کند دو شاخه متضاد را ادغام کند و در صورت شکست، مداخله دستی مورد نیاز است.
تقسیم بندی (Sharding)
هنگامی که اندازه داده از ظرفیت کلی یک محیط چند گره تکراری فراتر می رود، تقسیم داده ها اجتناب ناپذیر می شود. Sharding به معنای توزیع داده ها در چندین گره است، بنابراین هر نمونه فقط شامل یک زیر مجموعه از داده های کلی است.
به طور سنتی، پایگاه های داده رابطه ای پارتیشن بندی افقی را برای توزیع داده ها در چندین جدول در یک سرور پایگاه داده ارائه می دهند. برخلاف پارتیشن بندی افقی، اشتراک گذاری به یک توپولوژی سیستم توزیع شده نیاز دارد تا داده ها در چندین ماشین پخش شوند.
هر Shard باید مستقل باشد زیرا یک تراکنش کاربر فقط می تواند از داده های درون یک Shard استفاده کند. پیوستن بین خرده ها معمولاً ممنوع است زیرا هزینه قفل توزیع شده و سربار شبکه منجر به زمان پاسخ طولانی تراکنش می شود.
با کاهش اندازه داده در هر گره، ایندکس ها به فضای کمتری نیز نیاز دارند و بهتر می توانند در حافظه اصلی قرار بگیرند. با داده های کمتر برای پرس و جو، زمان پاسخ تراکنش نیز می تواند کوتاه تر شود. توپولوژی معمولی اشتراک گذاری حداقل شامل دو مرکز داده جداگانه است.
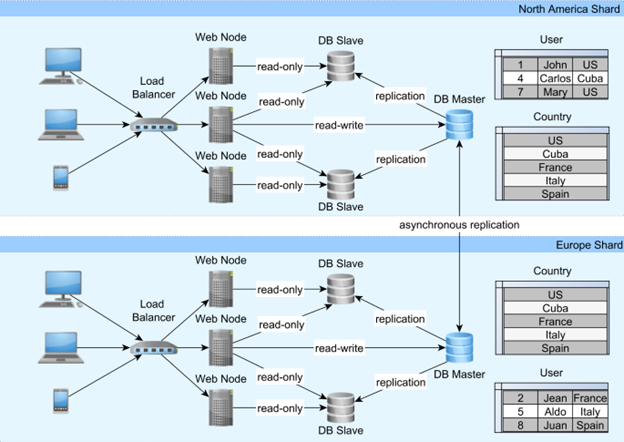
هر مرکز داده می تواند یک منطقه جغرافیایی اختصاصی را ارائه دهد، بنابراین بار در مناطق جغرافیایی متعادل است. همه جداول نیازی به پارتیشن بندی بر روی خرده ها ندارند، جدول های کوچکتر در هر پارتیشن کپی می شوند. برای همگام نگه داشتن خردهها، میتوان از مکانیزم تکثیر ناهمزمان استفاده کرد.
در نمودار قبلی، جدول کشور از یک مرکز داده به مرکز داده دیگر منعکس شده است و پارتیشن بندی فقط در جدول کاربر انجام می شود. برای از بین بردن نیاز به پردازش داده های بین Shard، هر کاربر به همراه تمام داده های مربوط به کاربر فقط در یک مرکز داده قرار می گیرد.
در تلاش برای افزایش ظرفیت سیستم، Sharding معمولا آخرین راهحل است که پس از اتمام تمام گزینههای موجود دیگر، مانند:
بهینه سازی لایه داده برای ارائه زمان پاسخ تراکنش کمتر
مقیاس بندی هر گره تکرار شده به یک پیکربندی مقرون به صرفه
اضافه کردن گرههای تکراری بیشتر تا زمانی که تأخیرهای همگامسازی شروع به کاهش به زیر یک آستانه قابل قبول کنند.
اشتراک گذاری خودکار خوشه MySQL
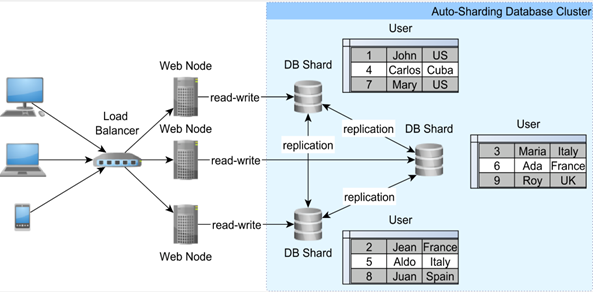
توپولوژی اشتراک خودکار مشابه معماری Multi-Master Replication است زیرا می تواند با توزیع بار ورودی به چندین ماشین، توان عملیاتی را افزایش دهد. در حالی که در یک محیط تکثیر شده MultiMaster، هر گره کل پایگاه داده را ذخیره می کند، خوشه اشتراک گذاری خودکار داده ها را به گونه ای توزیع می کند که هر خرده تنها زیرمجموعه ای از کل پایگاه داده باشد.
در هر سیستم معین، رابطه نهایی بین زمان پاسخ و توان عملیاتی توسط قانون لیتل ارائه می شود و مقادیر بالای توان ورودی می تواند به دلیل اشباع منابع باعث رشد تصاعدی در زمان پاسخ شود.
با این وجود، هنگام برقراری یک اتصال پایگاه داده واحد، با کاهش میانگین زمان پاسخ تراکنش، تراکنش های بیشتری را می توان در یک واحد زمانی معین جای داد.
شرکت مهندس پیشگان آزمون افزار یاس، خدمات زیر را در حوزه ارزیابی و پایش کارایی نرم افزار ارائه می دهد:
آموزش روشهای ارزیابی کارایی سامانه های نرم افزاری از طریق آزمونهای بار و فشار
اجرای آزمونهای بار و فشار برروی سامانه های نرم افزاری
تهیه و آموزش ابزارهای تست پرفورمنس (تست بار و فشار) همچون WPLT و LoadTest
پایش و مانیتورینگ شاخص های کارایی سامانه های نرم افزاری از طریق ابزارهای مدیریت کارایی همچون AppDynamicsو DynaTrace
نویسنده : شرکت مهندس پیشگان آزمون افزار یاس
![]() مراجع
مراجع
[1]-https://msdn.microsoft.com/en-us/library/ms190219.aspx
[2]-http://www.perfdynamics.com/Manifesto/USLscalability.html
[3]-http://en.wikipedia.org/wiki/Amdahl%27s_law
[4]-http://radar.oreilly.com/2009/06/bing-and-google-agree-slow-pag.html
[5]-https://www.facebook.com/note.php?note_id=409881258919
[6]-http://stackexchange.com/performance
[7]-http://blog.codinghorror.com/scaling-up-vs-scaling-out-hidden-costs/
[8]-https://www.mysql.com/products/cluster/scalability.html
[9]-http://dev.mysql.com/doc/mysql-cluster-excerpt/5.6/en/mysql-cluster-ndb-innodb-engines.html
[10]-https://dev.mysql.com/doc/refman/5.7/en/connection-threads.html
[11]-http://www.postgresql.org/docs/current/static/connect-estab.html
[11]-http://docs.oracle.com/database/121/CNCPT/process.htm